
Book Talk: Enshittification
Virtual; November 21, 10am PT / 1pm ET REGISTER HERE Enshittification: it’s not just you—the internet sucks now. Here’s why, […]

Virtual; November 21, 10am PT / 1pm ET REGISTER HERE Enshittification: it’s not just you—the internet sucks now. Here’s why, […]

Join us in Charleston this November for a Preconference on making backlist monographs open access! Tuesday, November 4, 2025, 1pm-4pm

We recently received a question regarding the AI scraping of Institutional Repositories, by which we mean online digital archives that
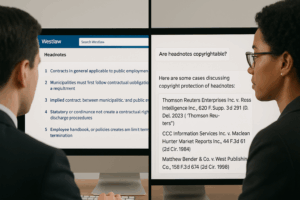
Yesterday Authors Alliance filed an amicus brief in Thomson Reuters v. ROSS Intelligence, the long-running lawsuit between Thomson Reuters, owner of Westlaw (a legal research platform) and ROSS Intelligence, an AI-powered start up legal research platform.

This fall semester, OCEAN and Authors Alliance will be co-hosting a full Discussion Series on AI and its implications for authors, artists, scholars, researchers and professionals working in libraries, archives and museums. We’re kicking off our fall programming with an introduction to the latest AI legal issues. This conversation is especially important as the law in this area rapidly evolves, with new legislative and regulatory approaches emerging that could significantly reshape how your organization navigates AI.

This is a post by Syn Ong, AI Policy Researcher at Authors Alliance. Authors increasingly rely on text and data mining (TDM) to analyze large corpora across disciplines. Our new working paper, Beyond the Exception: Licensing, Access, and the Realities of Text and Data Mining in the US, UK, and Singapore, finds that formal legal permissions alone do not secure usable access for TDM research. Instead, usable access turns on how statutory rules interact with private licenses, platform architectures, and technological protection measures (TPMs).

This is guest post by Amanda Wakaruk, Jane Secker, and Chris Morrison. Readers of this blog will know that authors are both users and creators of copyright-protected works. How confident are authors about their rights related to copyright? Is the fear of navigating copyright preventing non-infringing ‘user’ activities in higher education? What can we do to mitigate the damage to teaching and research caused by copyright anxiety and chill?

This event has passed. You can watching the recording here. On October 1 at 2pm ET / 11am PT, SPARC

This event has passed. You can watch the recording here. Join us and Internet Archive on September 25, 2025 for

We’ve written before about the use of contracts limiting author’s access to fair use, including how publisher contracts restrict innovation