Suno, Yout, Perplexity AI and §1201: AI Training and another piece of the DMCA November 21, 2025 By Authors Alliance
Big Ten Open Books: An Interview with Kate McCready (BTAA) and Charles Watkinson (UM) November 20, 2025 By Dave Hansen
The Morisky Medical Adherence Scale: a case study in using flimsy copyright claims to inhibit research November 7, 2025 By Dave Hansen
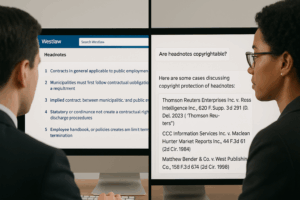
Authors Alliance Files Amicus Brief in Thomson Reuters v. Ross September 30, 2025 By Authors Alliance
Bartz v Anthropic Settlement Gets Preliminary Approval – Key Takeaways September 28, 2025 By Dave Hansen
Beyond the Exception: Licensing, Access, and the Realities of Text and Data Mining in the US, UK, and Singapore September 25, 2025 By Authors Alliance