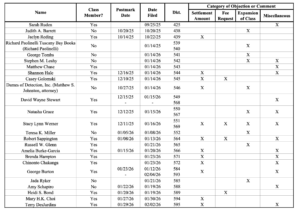
Bartz v. Anthropic Fairness Hearing: Final Reminder, 91.3% Claims Rate, and updates from the Docket May 14, 2026 By Authors Alliance
Bartz v. Anthropic Settlement Update: New Date and Time for the Fairness Hearing (you can join online) and Unsealed Objections April 14, 2026 By Authors Alliance
Will the Grammarly Lawsuit Show Us Yet Another Area Where Existing Law is Enough? (We Think So) April 9, 2026 By Authors Alliance